

Introdução
A Inteligência Artificial já não é experimental. Está incorporada nos nossos produtos digitais—alimentando recomendações, automatizando decisões e permitindo experiências de utilizador totalmente novas. À medida que os sistemas de IA se expandem, também cresce o seu impacto. É por isso que a União Europeia introduziu o Lei da IA da UE—o primeiro quadro legal especificamente concebido para regular os riscos da inteligência artificial.
Para as equipas de produto e inovação, isto não é apenas uma questão de conformidade—é estratégico. As decisões que toma hoje em torno do design, implementação e monitorização da IA determinarão não apenas a sua exposição legal, mas também a sua capacidade de construir produtos digitais escaláveis, éticos e confiáveis.
Introdução – porque isto é importante agora
A rápida adoção de Modelos de Linguagem Grandes (LLMs) está a transformar a engenharia de software. GPT-4, Claude, Mistral e outros já não são apenas APIs de backend — são ambientes de execução para lógica de linguagem humana.
No entanto, para a maioria dos engenheiros, o processo entre prompt do utilizador e resposta do modelo continua a ser uma caixa negra. Este artigo revela essa pilha oculta: as camadas de ferramentas, fluxos de dados, caching, armazenamentos vetoriais e estrutura UX que alimentam aplicações inteligentes.
Se está a implementar funcionalidades alimentadas por GPT, não está apenas a chamar uma API — está a criar uma experiência de IA. É hora de compreender o sistema por detrás.
O que acontece entre um prompt e uma resposta?
Quando um utilizador introduz texto, ocorre uma quantidade surpreendente de computação:
O frontend captura a entrada do utilizador.
Contexto ou documentos opcionais são recuperados.
Um prompt é construído (frequentemente com template).
Uma API LLM (como GPT-4) é chamada.
A resposta é analisada, validada e renderizada na UI.
Por detrás deste fluxo está uma pilha multicamada, não muito diferente de uma framework web moderna. Mas em vez de HTTP e bases de dados, está a lidar com linguagem, incerteza e inferência.
Componentes principais da pilha LLM
API LLM
Descrição:
O motor que gera texto
Ferramentas:
OpenAI, Anthropic, Mistral
Orquestração de prompts
Descrição:
Ferramentas para estruturar, encadear e testar prompts
Ferramentas:
LangChain, PromptLayer
Embeddings
Descrição:
Vetores que representam significado
Ferramentas:
OpenAI embeddings, Hugging Face
Base de dados vetorial
Descrição:
Motor de pesquisa e recuperação
Ferramentas:
Pinecone, weaviate, redis
Runtime frontend
Descrição:
Entrega de UX, gestão de latência
Ferramentas:
Vercel AI SDK, Next.js, SvelteKit
O papel da engenharia de prompts
Os prompts são as novas funções — desenha-os com intenção, parâmetros e proteções.
Um prompt bem estruturado pode:
Reduzir alucinações
Guiar a persona do modelo
Lidar com casos extremos (com instruções de fallback)
Considere usar ferramentas como PromptTemplates do LangChain ou mensagens de sistema do OpenAI para construir lógica de prompt testável e repetível.
Geração aumentada por recuperação (RAG)
RAG é uma técnica onde:
Armazena os seus dados específicos do domínio numa BD vetorial
Converte a entrada do utilizador num embedding
Recupera os k melhores fragmentos relevantes
Injeta isso no prompt enviado ao LLM
Ideal para aplicações como:
FAQs com IA, chat com documentos, pesquisa de conhecimento, etc.
Comece com:
LangChain + pinecone
Supabase pgvector
LlamaIndex para encaminhamento avançado
Latência e streaming no frontend
A inferência LLM pode demorar tempo. É por isso que o streaming no frontend é crítico.
Use:
- Vercel AI SDK para streaming em React
- Suspense + UIs de streaming para renderização em tempo real
- Padrões de UI otimista enquanto aguarda respostas LLM
O streaming parece mais rápido e constrói confiança do utilizador.
Key Takeaway
Limitação de taxa, caching e controlo de custos
Evite atingir limites de utilização ou estourar o seu orçamento:
Cache pares de prompt + resposta
Use embeddings para detetar similaridade semântica
Introduza retry + backoff exponencial em erros 429
Considere armazenar saídas de prompt comuns num CDN ou Edge KV.
Observabilidade em aplicações de IA
Como APM para modelos. Você vai querer saber:
Quando o modelo falha
Quais prompts estão causando erros
Quais saídas são de alto risco
Use:
Langfuse – monitoriza uso de prompts
PromptLayer – regista e versiona prompts
HoneyHive – ferramentas de feedback para correções com humano no ciclo
Colaboração Frontend + Backend
Engenheiros frontend agora influenciam:
Clareza do prompt
Experiência de streaming
Tratamento de erros e fallbacks
Relevância do contexto recuperado
Isto não é apenas infraestrutura de IA — é UX de IA.
Key Takeaway
Engenharia para gestão de alucinações
Ferramentas e práticas:
Prompts de sistema para reforçar honestidade
Limiares de confiança na saída
Mensagens de fallback e transparência
A confiança é crítica. Design em torno da imprevisibilidade.
Key Takeaway
Do protótipo à produção
Para passar de demo hackathon para produção:
Registe cada prompt + resultado
Construa pipelines de observabilidade
Teste em casos extremos
Considere atualizações do modelo + teste A/B
Implementar IA é um ciclo contínuo de produto, não uma integração única.
Key Takeaway
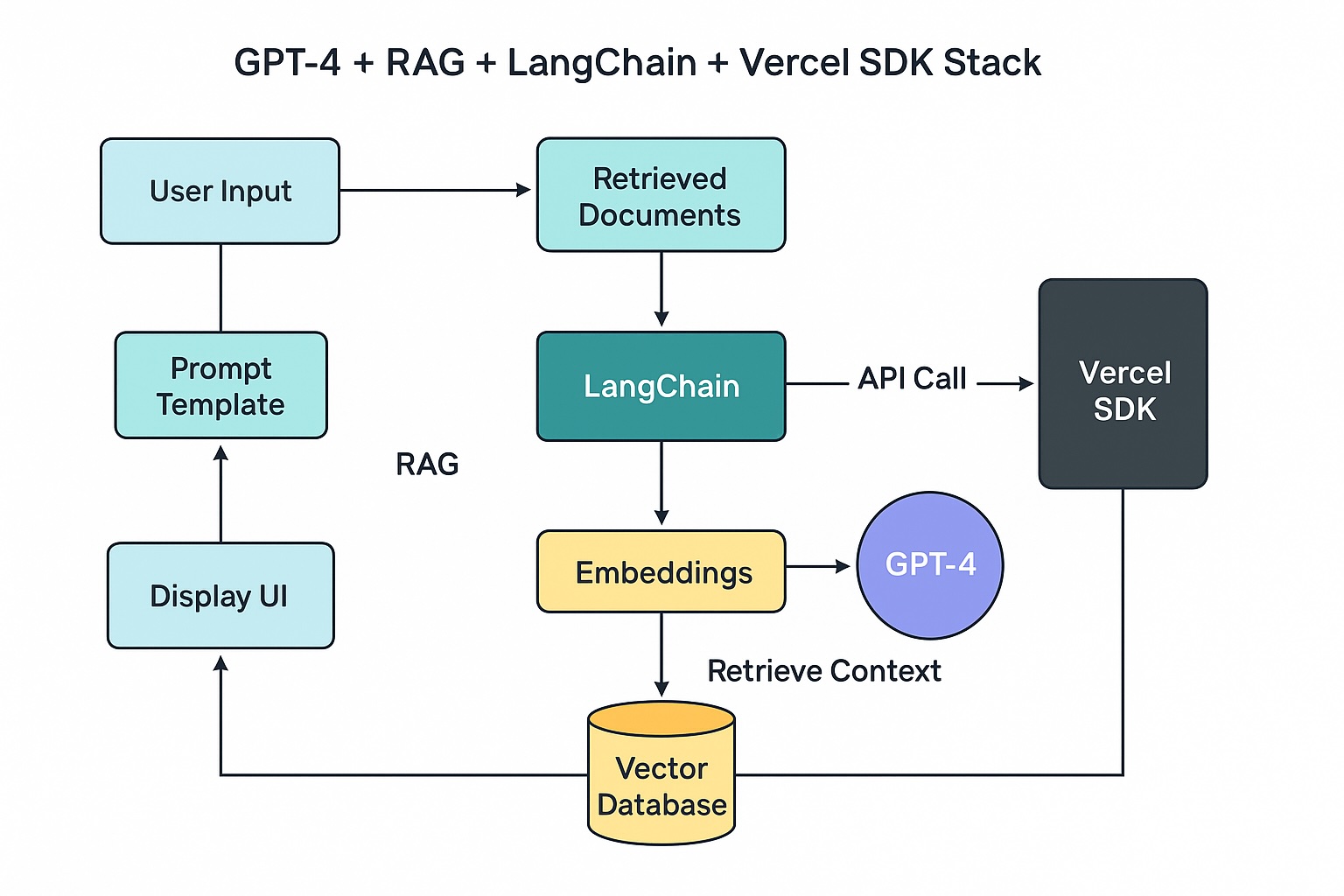
Exemplos de arquitetura do mundo real
Pilha GPT-4 + RAG + LangChain + vercel SDK
Implementar IA é um ciclo contínuo de produto, não uma integração única.
Key Takeaway
Armadilhas comuns a evitar
Proliferação de prompts sem observabilidade
Ignorar latência → UX degradada
RAG sem proteções = alucinações com autoridade
Tendências futuras na engenharia de aplicações IA
Agentes personalizados por utilizador
Inferência no dispositivo com modelos GGUF + WebAssembly
Sistemas de design nativos de IA com componentes conscientes de feedback
Conclusão – abraçando a camada de IA
O engenheiro moderno deve pensar além do CRUD. Com LLMs, a sua pilha inclui:
Linguagem
Relevância
Raciocínio
Capacidade de resposta
Compreender a pilha oculta torna-o não apenas um melhor programador — mas um melhor arquiteto de IA.
Key Takeaway
Perguntas frequentes
Como escolho entre RAG e fine-tuning?
RAG é mais fácil, mais rápido de iterar e mais barato. Fine-tuning só é necessário quando as saídas devem ser altamente estruturadas ou específicas do domínio.
Qual é a melhor maneira de fazer streaming do GPT-4 para o frontend?
Use Vercel AI SDK com React ou APIs de streaming do SvelteKit.
Que BD vetorial funciona melhor com Next.js?
Pinecone (hospedado) ou Supabase (pgvector auto-hospedado) integram bem.
Preciso do LangChain?
Nem sempre. Comece com APIs simples. Use LangChain quando a orquestração ficar complexa.
Posso executar GPT localmente?
Sim, com modelos como Mistral 7B ou Phi-3 via Ollama ou WebLLM, mas não GPT-4.
Como faço prompts com segurança para aplicações em produção?
Use mensagens de sistema, limites de tokens, APIs de moderação e filtros de saída.







