Introduction
Artificial Intelligence is no longer experimental. It’s embedded in our digital products—powering recommendations, automating decisions, and enabling entirely new user experiences. As AI systems scale, so does their impact. That’s why the European Union introduced the EU AI Act—the first legal framework specifically designed to govern the risks of artificial intelligence.
For product and innovation teams, this isn’t just a compliance issue—it’s strategic. The decisions you make today around AI design, deployment, and monitoring will determine not just your legal exposure, but your ability to build scalable, ethical, and trusted digital products.
Introduction – Why This Matters Now
The rapid adoption of Large Language Models (LLMs) is transforming software engineering. GPT-4, Claude, Mistral, and others are no longer just backend APIs — they’re runtime environments for human language logic.
And yet, for most engineers, the process between user prompt and model response remains a black box. This article reveals that hidden stack: the layers of tooling, data flows, caching, vector stores, and UX scaffolding that power intelligent applications.
If you’re shipping features powered by GPT, you’re not just calling an API — you’re curating an AI experience. It’s time to understand the system behind it.
What Happens Between a Prompt and a Response?
When a user enters text, a surprising amount of computation happens:
The frontend captures user input.
Optional context or documents are retrieved.
A prompt is constructed (often templated).
An LLM API (like GPT-4) is called.
The response is parsed, validated, and rendered in the UI.
Behind this flow sits a multi-layer stack, not unlike a modern web framework. But instead of HTTP and databases, you’re dealing with language, uncertainty, and inference.
Core Components of the LLM Stack
LLM API
Description:
The engine generating text
Tools:
OpenAI, Anthropic, Mistral
Prompt Orchestration
Description:
Tools to structure, chain, and test prompts
Tools:
LangChain, PromptLayer
Embeddings
Description:
Vectors representing meaning
Tools:
OpenAI embeddings, Hugging Face
Vector Database
Description:
Search & retrieval engine
Tools:
Pinecone, Weaviate, Redis
Frontend Runtime
Description:
Delivering UX, managing latency
Tools:
Vercel AI SDK, Next.js, SvelteKit
The Role of Prompt Engineering
Prompts are the new functions — you design them with intention, parameters, and guardrails.
A well-structured prompt can:
Reduce hallucinations
Guide the model’s persona
Handle edge cases (with fallback instructions)
Consider using tools like LangChain’s PromptTemplates or OpenAI’s system messages to build testable, repeatable prompt logic.
Retrieval-Augmented Generation (RAG)
RAG is a technique where you:
Store your domain-specific data in a vector DB
Convert user input into an embedding
Retrieve the top-k relevant chunks
Inject that into the prompt sent to the LLM
Ideal for apps like:
AI FAQs, chat-with-docs, knowledge search, etc.
Start with:
LangChain + Pinecone
Supabase pgvector
LlamaIndex for advanced routing
Latency & Streaming in the Frontend
LLM inference can take time. That’s why frontend streaming is critical.
Use:
- Vercel AI SDK for streaming in React
- Suspense + streaming UIs for real-time rendering
- Optimistic UI patterns while waiting on LLM responses
Streaming feels faster and builds user trust.
Key Takeaway
Rate Limiting, Caching & Cost Control
Avoid hitting usage caps or blowing your budget:
Cache prompt + response pairs
Use embeddings to detect semantic similarity
Introduce retry + exponential backoff on 429 errors
Consider storing common prompt outputs to a CDN or Edge KV.
Observability in AI Applications
Like APM for models. You’ll want to know:
When the model fails
What prompts are causing errors
Which outputs are high risk
Use:
Langfuse – tracks prompt usage
PromptLayer – log and version prompts
HoneyHive – feedback tools for human-in-the-loop corrections
Frontend + Backend Collaboration
Frontend engineers now influence:
Prompt clarity
Streaming experience
Error handling and fallbacks
Relevance of retrieved context
This isn’t just AI infrastructure — it's AI UX.
Key Takeaway
Engineering for Hallucination Management
Tools and practices:
System prompts to reinforce honesty
Confidence thresholds on output
Fallback messages and transparency
Trust is critical. Design around unpredictability.
Key Takeaway
From Prototype to Production
To move from hackathon demo to production:
Log every prompt + outcome
Build observability pipelines
Test on edge cases
Consider model updates + A/B test
Shipping AI is an ongoing product loop, not a one-time integration.
Key Takeaway
Real-World Architecture Examples
GPT-4 + RAG + LangChain + Vercel SDK Stack
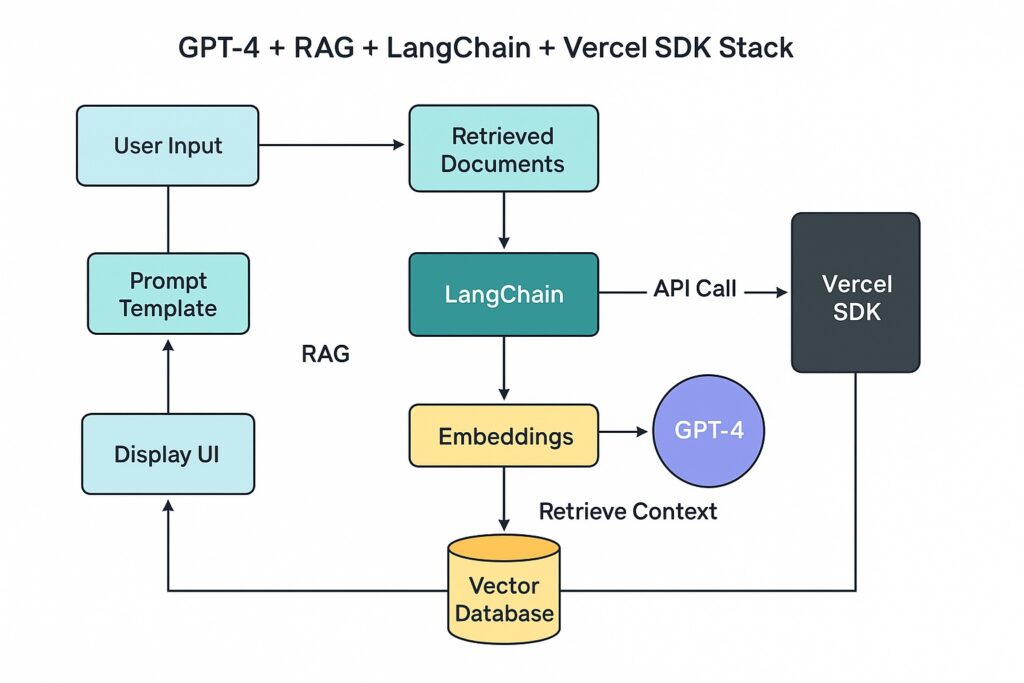
Shipping AI is an ongoing product loop, not a one-time integration.
Key Takeaway
Common Pitfalls to Avoid
Prompt sprawl without observability
Ignoring latency → degraded UX
RAG without guardrails = hallucinations with authority
Future Trends in AI App Engineering
Personalised agents per user
On-device inference with GGUF models + WebAssembly
AI-native design systems with feedback-aware components
Conclusion – Embracing the AI Layer
The modern engineer must think beyond CRUD. With LLMs, your stack includes:
Language
Relevance
Reasoning
Responsiveness
Understanding the hidden stack makes you not just a better coder — but a better AI architect.
Key Takeaway
FAQ
How do I choose between RAG and fine-tuning?
RAG is easier, faster to iterate, and cheaper. Fine-tuning is only needed when outputs must be highly structured or domain-specific.
What’s the best way to stream GPT-4 to the frontend?
Use Vercel AI SDK with React or SvelteKit’s streaming APIs.
What vector DB works best with Next.js?
Pinecone (hosted) or Supabase (self-hosted pgvector) integrate well.
Do I need LangChain?
Not always. Start with plain APIs. Use LangChain when orchestration gets complex.
Can I run GPT locally?
Yes, with models like Mistral 7B or Phi-3 via Ollama or WebLLM, but not GPT-4.
How do I prompt safely for production apps?
Use system messages, token limits, moderation APIs, and output filters.



